Open Source
Over the last few years, I have developed several open-source packages that used widely by the community. You can find an overview of these projects and packages here.

BERTopic
BERTopic is a novel topic modeling technique that leverages BERT embeddings and c-TF-IDF to create dense clusters allowing for easily interpretable topics.






PolyFuzz
PolyFuzz performs fuzzy string matching, string grouping, and contains extensive evaluation functions.
PolyFuzz is meant to bring fuzzy string matching techniques together within a single framework.





KeyBERT
KeyBERT is a minimal and easy-to-use keyword extraction technique that leverages BERT embeddings to create keywords and keyphrases that are most similar to a document.




Concept
Concept introduces the concept of Concept Modeling. It takes inspiration from topic modeling techniques to cluster images, find commonalities (i.e. concepts) and create a multimodal representation.


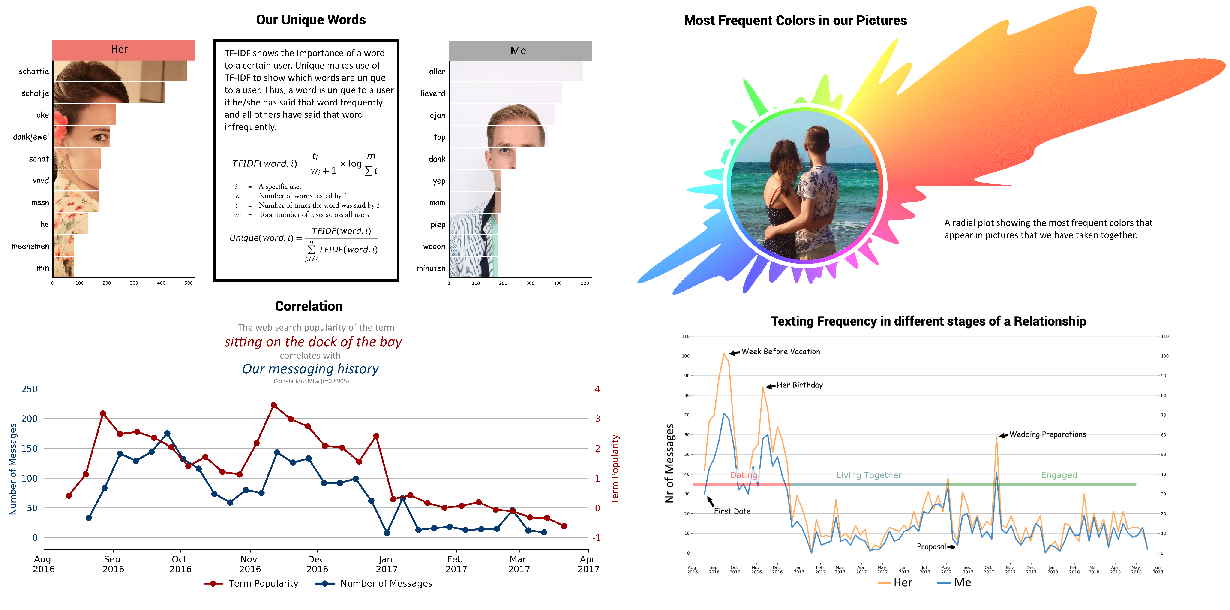
SoAn
Created a package that allows in-depth analyses (sentiment analysis, topic modelling, etc.) on whatsapp conversations.



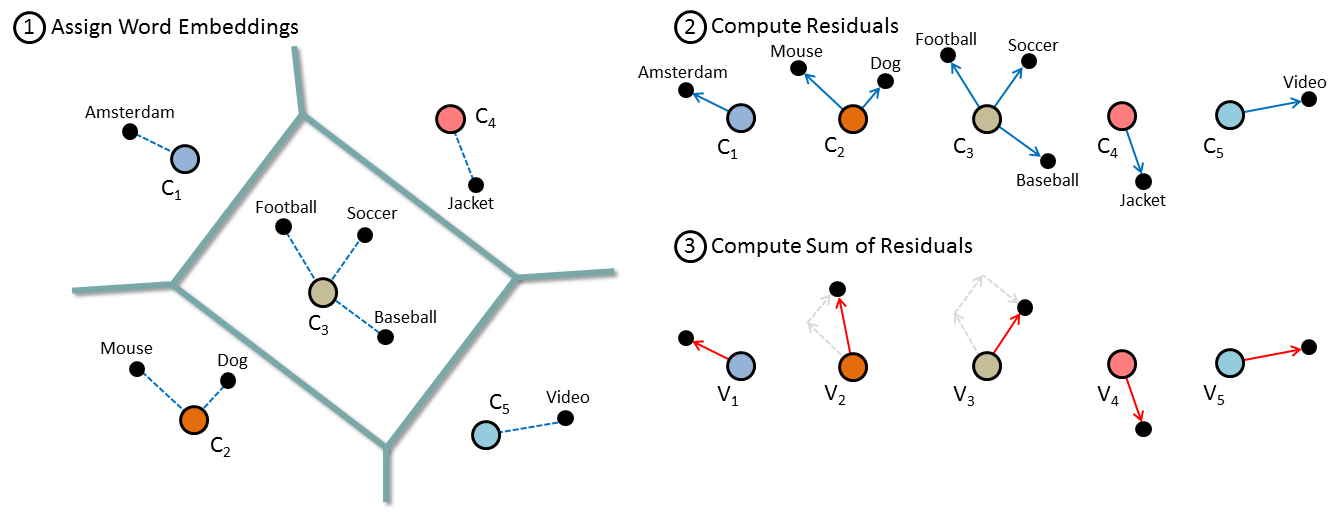
VLAC
Leveraging clusters of word embeddings to create features from a collection of documents allowing for classification of documents.




ReinLife
Using Reinforcement Learning, entities learn to survive, reproduce, and make sure to maximize the fitness of their kin.




Analyses
A small selection of projects and analyses I have done in the past to further develop my Data Science skills in my early career. It's nice to see where I started and how I ended.

Reviewer
A package for scraping user reviews from IMDB, generate C-TF-IDF based word clouds, and extract popular characters from reviews.




Disney
Tournament brackets are generated based on a seed score calculated through scraping data from IMDB and RottenTomatoes.


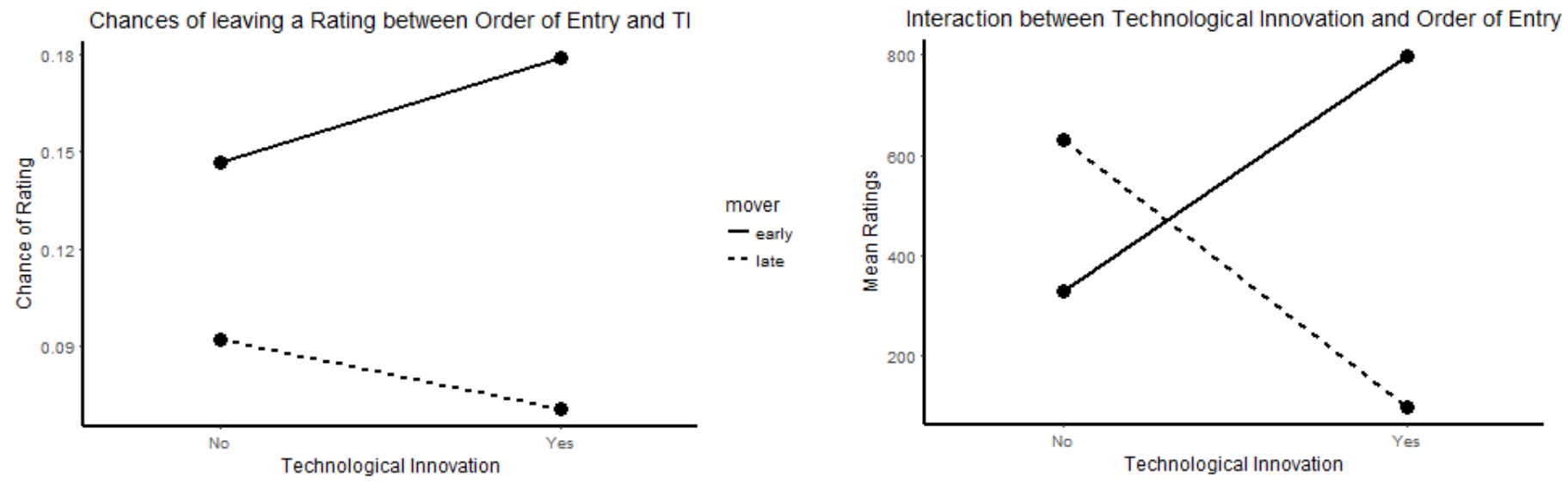
Hurdle Model
Used Apple Store data to analyze which business model aspects (entry timing and technological innovation) influence performance of mobile games.


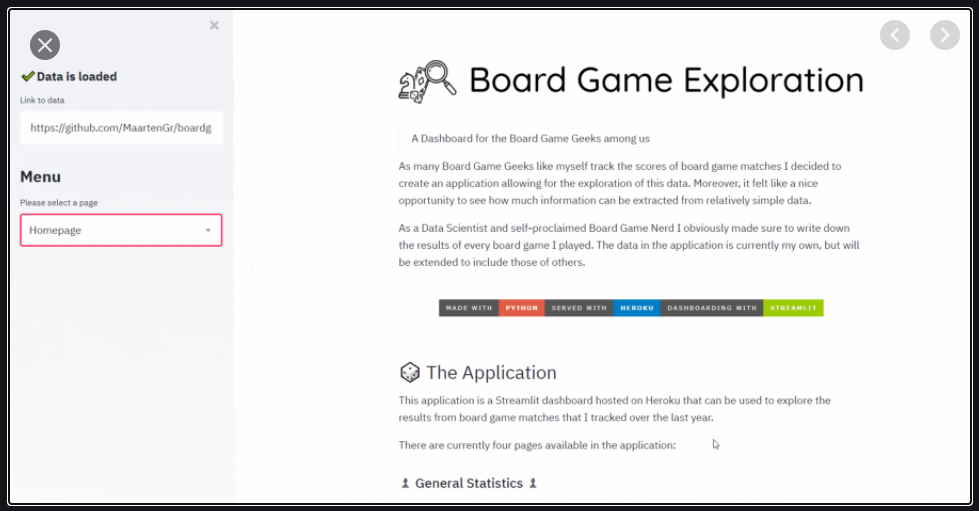
Boardgame Exploration
Created an application for exploring board game matches that I tracked over the last year. Streamlit and Heroku were used for deployment.


