Monitoring your Machine Learning Model
Over the last few years, Machine Learning and Artificial Intelligence have become more and more a staple in organizations that leverage their data. With that maturity came new challenges to overcome such as deploying and monitoring Machine Learning models.
Although deploying and monitoring software has been a well-tested practice, doing so for Machine Learning models has turned out to differ significantly. Monitoring your model can help you understand how accurate your predictions are over time.
Prevent erroneous predictions by monitoring your model
From personal experience, it seems that there are many organizations, mostly SME’s, that are now facing the challenges with this production stage of Machine Learning.
This article will focus on monitoring your Machine Learning model in production. However, if you are not familiar with deploying your model, I would advise you to look at the following article to get you up to speed.
NOTE: There is no one right way to monitor your model. This article merely serves as food for thought when designing your monitoring framework. Your miles may vary depending on the solution you’re working on.
1. Why monitor your Model?
All production software is prone to failure and every software company knows that it is important to monitor its performance to prevent problems. Typically, we monitor the quality of the software itself whereas, in the context of Machine Learning, one might focus more on monitoring the quality of predictions.
Not all data is created equal
There are several reasons why you would want to monitor your model:
-
The relationship between your model and the input data changes
-
The distribution of your data changes such that your model is less representative
-
Change in measurements and/or user base which changes the underlying meaning of variables
Drift
At the base of the above reasons, you can typically find the cause in drift. In its essence, drift is the phenomenon of changes in the statistical properties of your data that causes your predictions to degrade over time. In other words, since data is always changing, drift occurs naturally.

Take, for example, data from customers on an online store. A predictive model may use features such as their personal information, buying behavior, and money spent on advertisements. Over time, these features may not represent the features as they were originally trained on.
Drift is often referred to as concept drift, model drift, or data drift
It is important to monitor your model to make sure that the data input is similar to that used when training.
Why not just retrain your model?
Although retraining a model sounds like it is always a good idea, it might be a bit more nuanced than that!
What if you do not have timely labels? If your prediction is weeks in the future, it will be difficult to validate your model in practice as you need to wait weeks for the ground truth.
Or… what if you automatically retrain your model only to have it running for 10 hours before retraining it the next day? This could cost the organization significant computing time while having a marginally positive effect.
Or… what if you retrain a model in an online fashion only to have its performance degrade due to the focus on only newly added data?
Blindly retraining a model could lead to more costs, time waisted, or even a worse model. By monitoring your model you can be more precise in deciding the best method and time for retraining.
2. Monitoring
There is a huge amount of variations in methods for monitoring your deployed models. In practice, it will mostly depend on your application, model type, performance measures, and data distribution. However, there are a few things that you see most often when monitoring your model.
Monitor Predictions
If you are lucky, there is little time between your prediction and what you aim to predict. In other words, after making a prediction, you will quickly have the true labels. In that case, it is a simple matter of monitoring standard performance measures such as accuracy, F1-score, and ROC AUC.
However, when you do not have timely labels, performance measures cannot be used (e.g., disease prediction) and you would have to look at other methods:
-
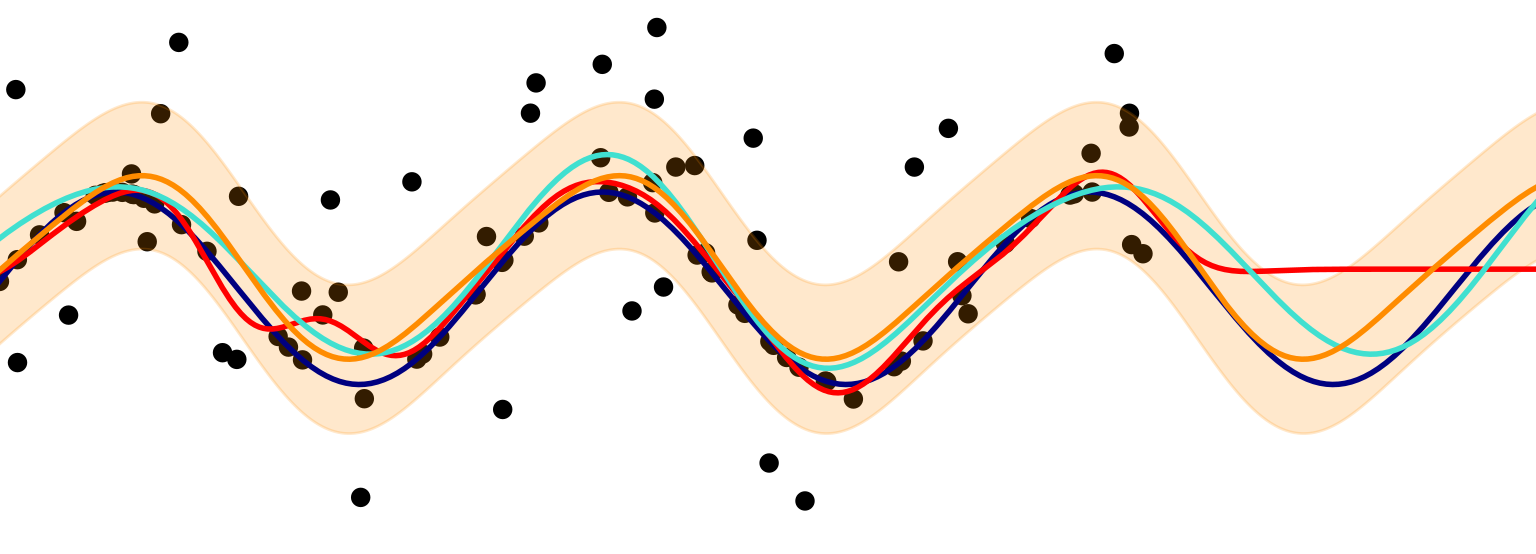
Distribution of predictions * You can use the distribution and frequency of predictions in regression and classification tasks to track whether the new set of predictions has a similar distribution to the training data. A significant deviation might indicate degradation in performance.
-
Prediction probabilities Many machine learning models can output classification probabilities. These indicate how “certain” a model is that this is the correct prediction. If these probabilities are relatively low, then the model might be struggling in deployment.
*NOTE: If you want to compare distributions, then we are typically looking at statistical tests such as the student’s t-test or the non-parametric Kolmogorov Smirnov. This might help you select the right statistical test for your data.
Monitor Input
If you have timely labels or not, it is often good practice to also monitor the input of your model. This helps you understand what is typically fed to your model and can help you track the deterioration of your predictions.
Methods include:
Distribution of features As with the predictions, you can use the distribution input data to track whether it has a similar distribution to the training data. If you find a significant difference, this might indicate that your training data is not representative of what you find in production.
Outlier detection Depending on your preprocessing steps, you typically do not allow certain values to be used in your prediction model. The number of categories in a variable might increase over time which your model did not anticipate.
Human Monitoring

In the age of automation, why would I suggest manual human monitoring? Especially when human behavior is extremely sensitive to errors?
Well… although human monitoring should be a last resort, there are some cases where it would be beneficial to have a human take a look at the predictions a model generates. If a monitored prediction is way off even though it had a probability of over 90%, then it would be nice if these exceptions are looked over by a human.
Human monitoring might even be necessary when you do not have the ground truth labels of predictions in practice.
3. Shadow mode
Whenever you want to deploy a retrained model, you might want to hold off deploying it to production. Instead, deploying it in shadow mode might be preferred. Shadow mode is a technique where you run production data through a newly trained model without giving the predictions back to the user.

Shadow mode allows you to simultaneously run both models while testing the performance of the newer model in a production environment. You can store its predictions to monitor its behavior before actually deploying to production.
Moreover, you can use this mode to check whether the model works as intended without the need to mimic a production environment as it is technically a copy of production.