6 Lessons I learned from developing Open-Source Projects
Open-source is such an amazing concept! By bundling the sources, skills, and knowledge of an entire community, tools can be created that we could have not made in isolation. The tools that come out of these collaborations are truly more than the sum of their parts.

As a result, we data scientists use this freely available software that is driving so many technologies whilst still having the opportunity to be involved in its development.
Over the last few years, I was fortunate enough to be involved in open-source and had the opportunity to develop and main several packages!
Developing open-source is more than just coding
During this time, there were plenty of hurdles to overcome and lessons to be learned. From tricky dependencies and API design choices to communication with the user base.
Working on open-source, whether as an author, maintainer or developer, can be quite daunting! With this article, I share some of my experiences in this field which hopefully helps those wanting to develop open-source.
1. Documentation is underrated
When you create open-source software, you are typically not making the package exclusively for yourself. Users, from all types of different backgrounds, will be making use of your software. Proper documentation comes a long way in helping those users get started.

However, do not underestimate the impact documentation can have on the useability of your package! You can use it to explain complex algorithms, give extensive tutorials, show use cases, and even allow for interactive examples.
Especially data science-related software can be difficult to understand when it involves complex algorithms. Approaching these explanations like a story has often helped me in making them more intuitive.
Trust me, writing good documentation is a skill in itself.
Another benefit is that writing solid documentation lowers the time spent on issues. There is less reason for users to ask questions if they can find the answers in your documentation.

An overview of how KeyBERT works is found in the documentation. However, creating documentation is more than just writing it. Visualizing your algorithm or software goes a long way in making it intuitive. You can learn quite a lot from Jay Alammar when you want to visualize algorithmic principles in your documentation. His visualizations even ended up in the official Numpy documentation!
2. Community is everything
Your user base, the community, is an important component of your software. Since we are developing open-source, it is safe to say that we want them to be involved in the development.

By engaging with the community you entice them to share issues and bugs, but also feature requests and great ideas for further development! All of these help in creating something for them.
The open-source community is truly more than the sum of its parts
Many core features in BERTopic, like online topic modeling, have been implemented since they were highly requested by its users. As a result, the community is quite active and has been a tremendous help in detecting issues and developing new features.
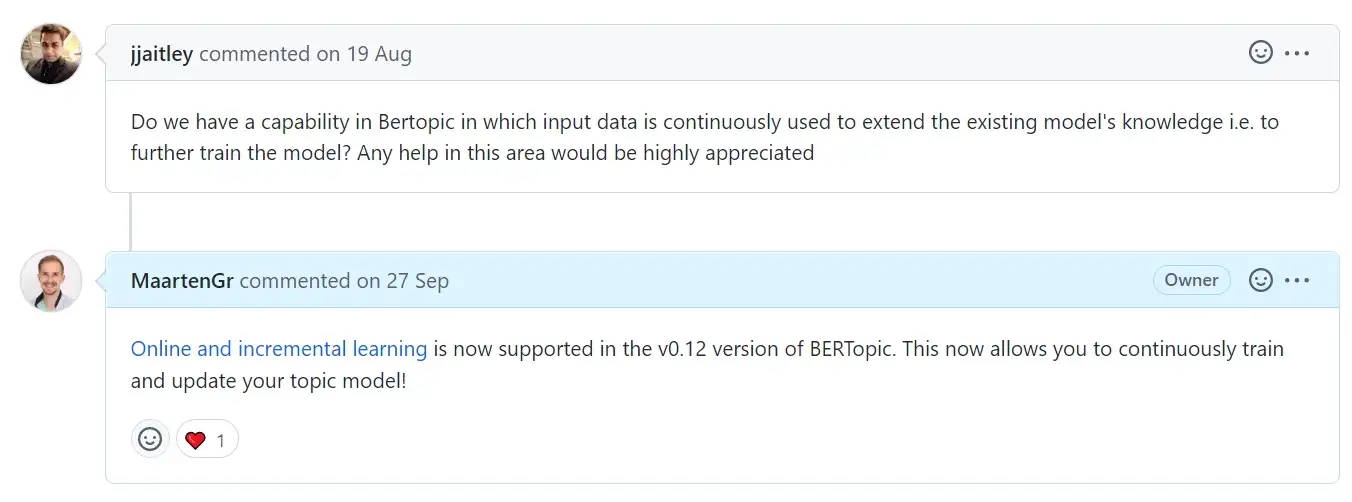
Implementing feature requests by the community goes a long way! An excerpt of the discussion here.
3. Great learning opportunity
Whether your package will be used millions of times or just a few, creating one is an excellent opportunity to learn more about open-source, MLOps, unit testing, API design, etc. I have learned more about these skills in developing open-source than I would have in my day-to-day job.

There is also a huge learning opportunity from interacting with the community itself. They are the ones that tell you which designs they like or not. At times, I have seen the same issue popping up several times over the course of a few months. This indicates that I should rethink the design as it was not as user-friendly as I had anticipated!
On top of that, developing open-source projects has given me the opportunity to collaborate with other developers.
4. It can be stressful
Working on your own open-source projects outside of work does come with its disadvantages. To me, the most significant one is that maintaining the package, answering questions, and participating in the discussions can be quite a lot of work.

It definitely helps if you are intrinsically motivated but it still takes quite some time to make sure everything is held together.
Fortunately, you can look towards your community to help you out when answering questions, showcasing use cases, etc.
Over the course of the last few years, I have learned to be a bit more relaxed when it comes to breaking changes. Especially when it concerns dependencies, sometimes there is just so much you can do!
5. Github stars do not equal quality!
Knowing how often your package is used is a tremendous help in understanding how popular it is. However, many are still using Github stars to equate a package with quality and popularity.

Make sure to define the right metric. GitHub stars can be exaggerated simply due to proper marketing. Many stars do not imply popularity. As data scientists, we must first understand what it is that we are exactly measuring. GitHub stars are nothing more than a user giving a star to a package. It does not even mean that they have used the software or that it is actually working!

The number of downloads for KeyBERT. A much better indicator than Github stars. Technically, I can pay a thousand people to star my repos. Instead, I focus on a variety of statistics, like downloads and forks, but also the number of issues I get on a daily basis.
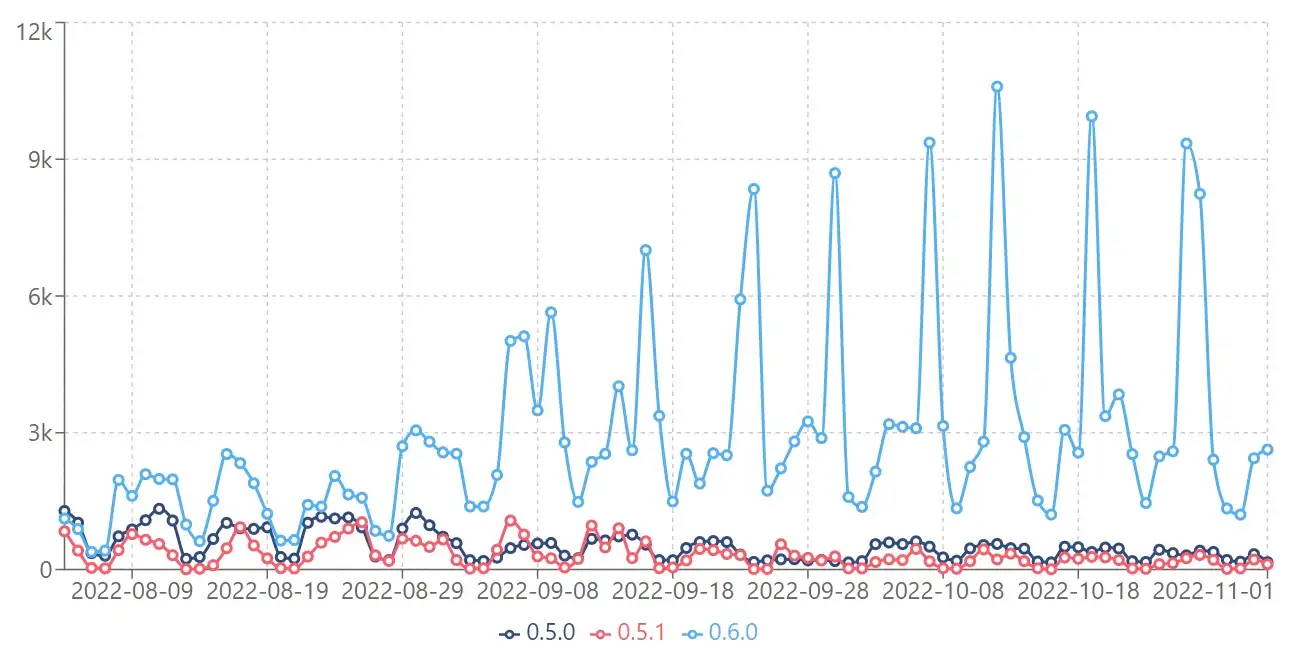
For example, it is great if your packages get featured on Hacker News but it does not tell you if it is consistently used.
6. The Psychology of API Design
As a psychologist, I tend to focus a lot on the design of my packages. This includes things like documentation and tutorials but it even translates to how I code.

Making sure that the package is easy to use and install makes adoption much simpler. Especially when you focus on design philosophies such as modularity and transparency, some packages become a blast to use.

The modular design of topic modeling with BERTopic. Taking the perspective of a psychologist whilst developing new features has made it much easier to know what to focus on. What are users looking for? How can I code in a way that explains the algorithm? Why are users actually using this package? What are the major disadvantages of my code?
Taking the time to understand the average user drives adoptation
All of the above often leads to a basic but important rule; Keep It Super Simple
Personally, if I find a new package difficult to install and use, I am less likely to adopt it in my workflow.